AcastaCrafter CS 175: Project in AI
Final Report
Video

Project Summary
Our project aimed to develop an AI agent capable of autonomously navigating and performing tasks in a Minecraft environment, specifically focusing on the “MineRLTreechop-v0” environment. Initially, we intended to train an agent to obtain diamonds in a complex, underground setting. However, due to various technical challenges, including compatibility issues with HPC3 and the complexity of the environment, we shifted our focus to mastering the simpler task of chopping trees.
The primary objective became training an agent to efficiently locate and chop down trees in the “MineRLTreechop-v0” environment. This environment provides only visual input (64x64 pixel images) and requires the agent to learn a sequence of actions to navigate and interact with the environment to obtain logs.
The challenge of this task lies in the sparse reward structure and the complexity of visual navigation. The agent must learn to interpret visual cues, make decisions about movement and interaction, and persist through long sequences of actions to receive a single reward. The task is not trivial because it requires the agent to learn complex behaviors from pixel-level data and sparse rewards, making it a suitable problem for AI/ML algorithms.
Approaches
Baseline Approach: Random Actions
Initially, we established a baseline by implementing an agent that took random actions. This approach provided a benchmark for comparing the performance of our trained models. The random agent’s performance was predictably poor, as it rarely succeeded in locating or chopping down trees, highlighting the difficulty of the task without learning.
Proposed Approach: Behavior Cloning and Proximal Policy Optimization (PPO)
Our main approach involved a two-stage training process: behavior cloning (BC) followed by Proximal Policy Optimization (PPO).
- Behavior Cloning (BC):
- We utilized the MineRL dataset, which includes recordings of human players interacting with the environment.
- We implemented a data preprocessing script (
gen_pretrain_data.py) to convert the human player actions into a discrete action space compatible with our agent. - We used the preprocessed dataset to train a model using behavior cloning, aiming to initialize the agent with human-like behavior.
- The BC pre-train was done by using stable-baselines with tensorflow 1.x.
- Proximal Policy Optimization (PPO):
- After the BC stage, we fine-tuned the model using PPO, a reinforcement learning algorithm.
- We implemented custom wrappers (
wrappers.py) to shape the observation and action spaces, making them suitable for our agent. - We used stable-baselines3 with PPO, pytorch, and tensorflow 2.x for the RL training.
- We experimented with different hyperparameters, including learning rates and batch sizes, to optimize performance.
Challenges and Insights
- Sparse Rewards: The “MineRLTreechop-v0” environment provides very sparse rewards, making it difficult for the agent to learn. We attempted to address this by pre-training with behavior cloning, but the underlying challenge persisted.
- Action Space: We faced challenges in defining an effective action space. Initially, we used a large continuous action space, but we found that a discrete action space with a limited set of actions was more effective.
- Observation Space: The limited 64x64 pixel observation space posed a challenge. We considered scaling up the observation space but were limited by computational resources.
- Library Compatibility: We encountered numerous compatibility issues with different versions of libraries (MineRL, TensorFlow, Stable Baselines). We spent significant time troubleshooting these issues, which impacted our progress.
- OpenAI VPT Model: We explored fine-tuning the OpenAI VPT pre-trained model but found its architecture too complex to integrate with our setup within the given timeframe.
- Evaluation Metrics: We struggled with evaluating the agent’s performance due to issues with the environment’s reward structure and episode termination. We found that the environment sometimes terminated unexpectedly, affecting our evaluation metrics.
Evaluation
We evaluated our agent’s performance using both quantitative and qualitative methods.
Quantitative Evaluation
- We tracked the number of logs collected per episode.
- We compared the performance of our trained models with the baseline random-action agent.
- We plotted the episode reward over training steps to see the learning progress.
- Due to environment termination issues, getting consistent reward values was very difficult.
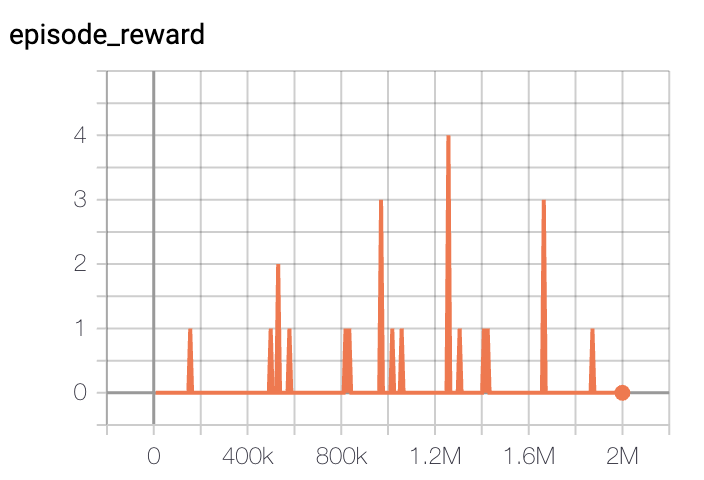
Our best agent could collect more than 20 logs in 2_000_000 steps while the random agent (baseline) couldn’t collect any log.
Qualitative Evaluation
- We recorded videos of the agent’s behavior to visually assess its performance.
- We observed the agent’s ability to navigate towards trees and perform the chopping action.
- We successfully recorded one episode of the agent successfully chopping a tree.

References
- MineRL Documentation & GitHub: Installation guidance and training setup.
- Stable Baselines Documentation: Reinforcement learning algorithms and implementation details.
- OpenAI VPT Research Paper: Information on the pre-trained models. (https://github.com/openai/Video-Pre-Training)
- imitation library documentation: imitation learning from expert dataset.
- Stable-baselines documentation: behavior cloning pre-train.
- Stable-Baselines-Team/rl-colab-notebooks: Example of using BC pre-train with stable-baselines3.
- Stable-Baselines3 Imitation Learning Guide (https://imitation.readthedocs.io/en/latest/index.html)
- Reinforcement Learning Colab Examples (https://github.com/Stable-Baselines-Team/rl-colab-notebooks/blob/sb3/pretraining.ipynb)
- Schulman, J., et al. “Proximal Policy Optimization Algorithms.” arXiv preprint, 2017.
- OpenAI Gym and MuJoCo Documentation.
- TensorFlow/PyTorch Reinforcement Learning Libraries.
AI Tool Usage
- GitHub Copilot & ChatGPT: Assisting with debugging, coding, and understanding technical documentation. We used these tools to generate code snippets, explain error messages, and research relevant algorithms.